글 개요
이번 글에서는 pandas 라이브러리 기초적인 내용을 정리하려고 합니다. 이 글을 보고 누군가에게 도움이 된다면 좋을거 같습니다.
글 본문
데이터프레임
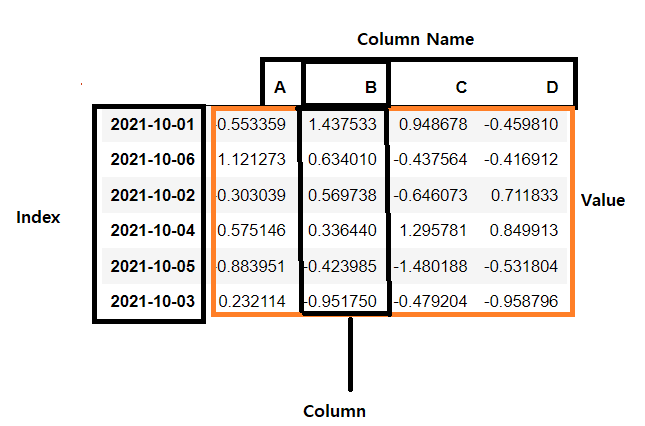
Column Name: 컬럼명입니다.
Column: A , B, C, D 하나하나가 컬럼입니다. 그 컬럼 하나하나가 pandas의 Series라고 한다. Series가 여러개 모여있으면 그게 데이터프레임 입니다.
Index: 2021-10-01 ~ 2021-10-03가 index 입니다. index를 통해 각 행에 접근할 수 있습니다.
CSV파일 읽기
판다스에서 csv파일을 읽을 수 있습니다.
import pandas as pd
# 한글이 깨지지 않았을 때
datas = pd.read_csv('csv파일경로/.csv')
# 한글이 깨졌을 때
1. datas = pd.read_csv('csv파일경로/.csv', encoding='utf-8')
2. datas = pd.read_csv('csv파일경로/.csv', encoding='cp949')보통 한글이 깨졌을 때 제 경험상 위 두가지 방법으로 해결이 되었습니다. 가끔가다가 utf-8로 해도 깨지는 경우가 있는데 그때 encoding 방식을 cp949로 시도해보세요.!
EXCEL 파일읽기
판다스에서는 csv파일 말고도 excel파일도 읽을 수 있습니다.
import pandas as pd
datas = pd.read_excel('excel 파일 경로/.xls')
excel파일은 원하는 column을 읽을 수 있는 옵션과 지우고 싶은 행을 지울 수 있는 옵션이 있습니다.
아래 데이터로 예를들겠습니다. 아래데이터 출처는 서울시 공공데이터 각 구별 cctv데이터 입니다.

위 데이터를 pandas로 읽게 되면 아래 형태처럼 읽어집니다.

엑셀 파일을 읽게되면 위형태 처럼 결과가 나옵니다. 엑셀에서 셀 병합된게 데이터와 함께 같이 나타나게 됩니다. 이럴때 처리하는 방법이 있습니다.
import pandas as pd
data= pd.read_excel('엑셀파일경로/.xls', header = 2, usecols="B, D, G, J, N")
header 옵션
header 옵션은 상위에서 지우고싶은 행까지 지울 수 있습니다. 위 코드에서는 header = 2 2행까지 지웁니다.
usecols 옵션
usecols은 보고싶은 컬럼을 선택할 수 있습니다.(엑셀시트 기준)
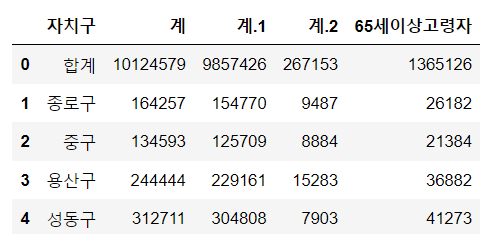
위에 코드를 실행하면 이렇게 깔끔한 코드를 볼 수 있습니다.
head()와 tail() 함수 기능
데이터를 읽다보면 상위 5개 혹은 맨끝 5개 데이터만 보고싶을 때가 있습니다.
import pandas as pd
data = pd.read_csv('파일.csv')
# 상위 5개까지만 보고싶을 때
data.head()
#맨끝 5개보고싶을 때
data.tail()
컬럼명 바꾸기
데이터프레임에 있는 컬럼명을 변경할 수 있습니다.
import pandas as pd
data = pd.read_csv('.csv', encoding = 'utf-8')
data.rename(
columns={data.columns[0]: '이름',
data.columns[1]: '나이',
data.columns[2]: '이메일'
},
inplace = True
)inplace = True 옵션을 주면 원본데이터에 적용이 됩니다.
정렬
pandas에서도 특정 컬럼기준으로 데이터프레임을 정렬할 수 있습니다.
import pandas as pd
data = pd.read_csv('.csv', encoding = 'utf-8')
# 오름차순 작은거에서 큰거
data.sort_values(by='소계', ascending = True).head()
# 내림차순 큰거에서 작은거
data.sort_values(by='소계', ascending = False).head()위 예시에서는 소계라는 컬럼 기준으로 데이터를 정렬했습니다.
데이터프레임 컬럼선택
데이터프레임에서 한 개의 컬럼명을 선택해야할 때가 있습니다. 아래방법을 사용해주세요.
import pandas as pd
df = pd.read_csv('data.csv', encoding = 'cp949')
#가상의 A 컬럼이 있다고 가정합니다.
# 첫 번째 방법
df['A']
# 두 번째 방법
df.A
# 두 개이상 컬럼 선택방법
df[['A', 'B']]
슬라이싱 선택 offset index
- [n:m] n부터 m -1까지 선택합니다.
- index나 column으로 slice를 경우 끝을 포함하여 결과를 출력합니다.
import pandas as pd
df = pd.read_csv('예상.csv', encoding = 'cp949')
loc ---> location
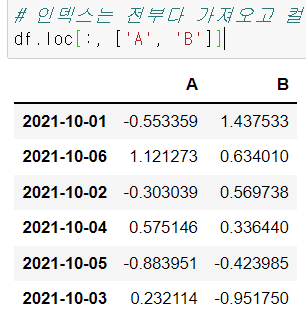
# index는 다 가져오고 컬럼은 A, B만 가져오는것다.
df.loc[:, ['A', 'B']] # 설명 1
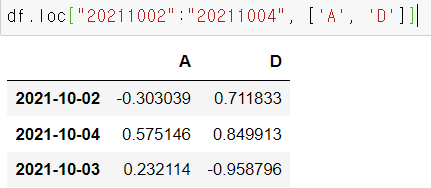
# 인덱스 중 2021102부터 2011004까지 만 가져오고 컬럼은 A와 D만 가져온다
df.loc["20211002":"20211004", ['A', 'D']] 설명 2
# index의 20211002부터 20211004까지 가져오고, 컬럼은 A부터 D까지 가져온다.
df.loc["20211002":"20211004", "A":"D"] # 설명 3
# 20211002 index를 선택하고 그중 A컬럼과 B컬럼을 가져온다.
df.loc['20211002', ['A','B']] # 설명 3-1

import pandas as pd
df = pd.read_csv('가상데이터.csv')
iloc ------> interger location
#컴퓨터가 인식하는 인덱스값으로 선택한다.
df.iloc[3] 설명1
# [행 열]
df.iloc[3:5, 0:2] 설명 2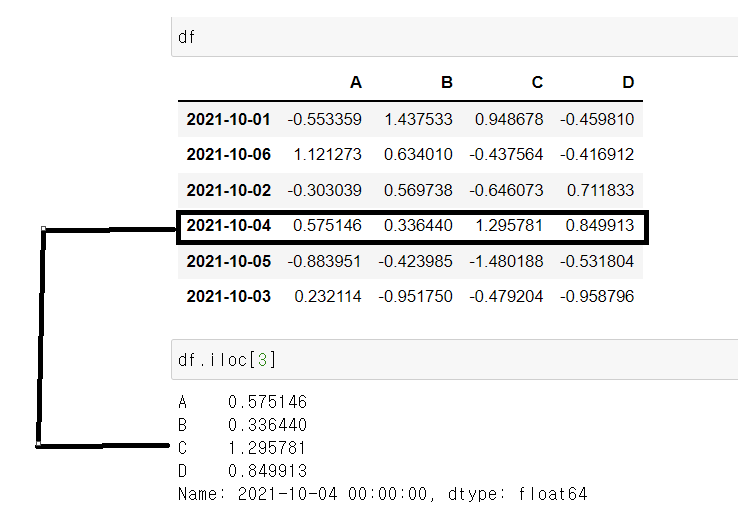

데이터프레임에서 조건으로 필터링하는 법 condition
어떤경우에는 특정 데이터들만 보고싶은 경우가 있습니다. 예를들어, 양수값만 보고싶다던지 등등 이러한 조건을 처리하는 방법이 있습니다.
import pandas as pd
df = pd.read_csv('data.csv')
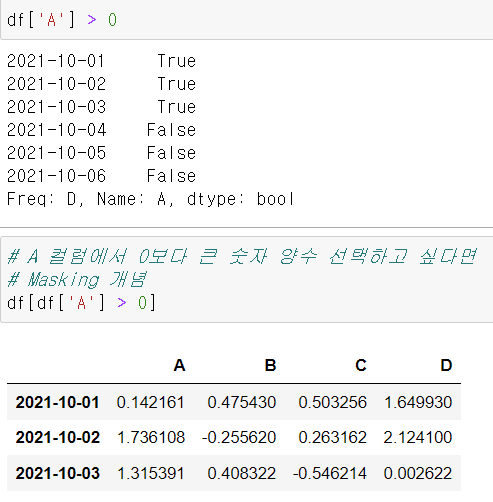
# A 컬럼의 데이터들 중에서 0보다 큰 데이터만 가져옵니다. 하지만 이 결과는 0보다 큰값은 True나오고
# 0보다 작은값들은 False로 출력이 됩니다.
# 여기에 masking작업을 해주면 0보다 큰값을 출력하는 데이터프레임 형태를 볼 수 있습니다.
df[df['A'] >0]
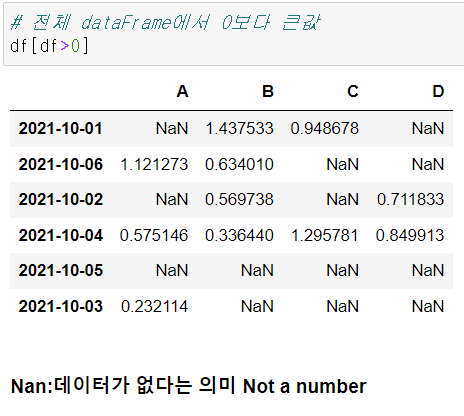
# 전체데이터에서 0보다 큰 값만 출력
df[df >0]
판다스에서 데이터 조건으로 검색하는 방법을 알았습니다. 다음 글에서도 판다스 기초문법을 이어서 작성하겠습니다.
저도 아직 많이 부족하기에 틀린부분이 있을 수 가 있습니다. 틀린부분이 있다면 말해주시면 감사합니다.
'Python' 카테고리의 다른 글
| 파이썬 matplotlib 기초 (0) | 2021.09.18 |
|---|---|
| pandas 기초정리 -2 (0) | 2021.09.16 |
| 파이썬-조건식 (0) | 2021.09.15 |
| 파이썬-연산자 (0) | 2021.09.15 |
| 정적타입언어 vs 동적타입언어 (0) | 2021.09.15 |




댓글