글 개요
https://yoo-young.tistory.com/19
Pandas - 기초 정리
글 개요 이번 글에서는 pandas 라이브러리 기초적인 내용을 정리하려고 합니다. 이 글을 보고 누군가에게 도움이 된다면 좋을거 같습니다. 글 본문 데이터프레임 Column Name: 컬럼명입니다. Column: A ,
yoo-young.tistory.com
이전에 작성했던 pandas 라이브럴 기초를 이어서 작성하려고 합니다.
글 본문
데이터프레임에 특정 요소가 있는지 확인할 때가 있습니다. 판다스에서도 특정 요소를 찾아주는 문법이 있습니다.
import pandas as pd
df = pd.read_csv('특정.csv')
df['E'].isin(['one', 'two'])
# 있으면 True 없으면 False
# True인 데이터만 가져오기
df[df['E'].isin(['one', 'two')]

특정 컬럼 제거함수
판다스에서도 특정 데이터를 제거해야할 때가 있습니다. 판다스에서는 데이터를 지우는데 두가지 방법이 있습니다.
1. del 삭제하기 원하는 컬럼
2. 데이터프레임.drop([삭제는 원하는컬럼], axis=1)
- axis= 0 행 기준 삭제 axis = 1 컬럼 기준 디폴트로 False로 되어있다.
import pandas as pd
df = pd.read_csv('특정.csv')
# 1. del 활용법
del df['E]
# 2. drop 활용법
df.drop(['E'], axis= 1)
apply() 함수
특정 컬럼의 데이터의 집계함수 정보를 알고싶을 때 사용하면 좋은 함수입니다.
import pandas as pd
import numpy as np
df = pd.read_csv('특정.csv')
# 합계
df['A'].apply('sum')
# 평균
df['A'].apply('mean')
# 최대
df['A'].apply('max')
# 최소
df['A'].apply('min')
------------------------------
numpy
# 합계
df['A'].apply(np.sum)
# 평균
df['A'].apply(np.mean)
# 표준편차
df['A'].apply(np.std)
함수를 custom하여 적용도 할 수 있습니다.
import pandas as pd
df = pd.read_csv('특정.csv')
# 데이터가 양수인지 아닌지 구분하는 함수
def checknum(num):
return 'plus' if num >0 else 'minus'
df['E'].apply(checknum)
데이터프레임 만들기
판다스로 데이터프레임 만드는 방법이 두가지가 존재합니다.
1. 딕셔너리안에 리스트형태로 데이터프레임 만들기
2. 리스트안에 딕셔너리형태로 데이터프레임 만들기
위 방법 두 가지 다 보여드리겠습니다.
import pandas as pd
첫 번째 방법
dataFrame1 = pd.DataFrame({
"key":['K0', 'K4', 'K2', 'K3'],
"A":['A0', 'A1', 'A2', 'A3'],
"B":['B0', 'B1', 'B2', 'B3']
})
# 2번째 방법
dataFrame2 = pd.DataFrame([
{"key":"K0" ,"C":"C0", "D":'D0'},
{"key":"K1" ,"C":"C1", "D":'D1'},
{"key":"K2" ,"C":"C2", "D":'D2'},
{"key":"K3" ,"C":"C3", "D":'D3'}
])
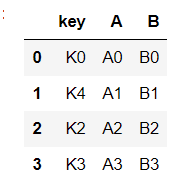

첫 번째 방법은 세로로 데이터가 만들어지고 두 번째 방법은 가로로 데이터가 만들어집니다.
이뿐만아니라 다양한 방법으로 데이터프레임을 만들 수 있습니다.
데이터프레임 합치기
판다스의 문법중 두 데이터프레임을 합치는 기능들이 있습니다.
1. pd.merge()
2. concat()
3. join()
위 3개중 첫 번째로 merge기능을 설명하려고 합니다. 일단, 두 데이터프레임을 만들어 보겠습니다.
import pandas as pd
firstDataFrame = pd.DataFrame({
"key":['K0', 'K4', 'K2', 'K3'],
"A":['A0', 'A1', 'A2', 'A3'],
"B":['B0', 'B1', 'B2', 'B3']
})
secondDataFrame = pd.DataFrame([
{"key":"K0" ,"C":"C0", "D":'D0'},
{"key":"K1" ,"C":"C1", "D":'D1'},
{"key":"K2" ,"C":"C2", "D":'D2'},
{"key":"K3" ,"C":"C3", "D":'D3'}
])
pd.merge(firstDataFrame, secondDataFrame, on='Key', how = 'left') # 설명 1두개의 데이터프레임을 만들었습니다. pd.merge()함수는 두 데이터프레임에서 기준을 잡고 데이터를 병합하는 방법입니다. 기준이 되는 컬럼이나 인덱스를 key값이라고 합니다. 그렇기 때문에 기준이 되는 key값은 두 데이터프레임에 포함이 되어야 합니다.
설명 1번 코드를 설명해보자면 firstDataFrame 데이터프레임과 secondDataFrame을 합치는데 그 기준이 Key라는 컬럼이고 왼쪽에 있는 데이터프레임 키값 기준으로 합친다라는 의미입니다.


위 이미지는 설명 1번 코드를 실행을 하였을 때 결과입니다. firstDataFrame쪽 기준으로 데이터를 병합을 하니 firstDataFrame값들이 secondDataFrame에 없으니 Nan값이 나타나는 것입니다. 즉, secondDataFrame에 K1값이 없기 때문에 Nan값이 나타난것입니다.
pd.merge()함수의 how 옵션은 4가지가 있습니다.
1. inner: 두 데이터프레임의 교집합만 병합됩니다.
2. outer: 두 데이터프레임의 합집합으로 병합됩니다.
3.right: 오른쪽 데이터프레임 key값기준으로 데이터가 병합됩니다.
4. left: 왼쪽 데이터프레임 key값 기준으로 데이터가 병합됩니다.
'Python' 카테고리의 다른 글
| 파이썬 matplotlib 기초-2 (0) | 2021.09.19 |
|---|---|
| 파이썬 matplotlib 기초 (0) | 2021.09.18 |
| Pandas - 기초 정리 (1) | 2021.09.16 |
| 파이썬-조건식 (0) | 2021.09.15 |
| 파이썬-연산자 (0) | 2021.09.15 |




댓글