글 개요
이번 포스팅에서는 Selenium의 기본 문법과 자주 사용되는 함수를 알아보겠습니다.
글 본문
현재 브라우저 창 크기 설정하기
driver.get_window_size(), driver.set_window_size(x, y), driver.maximize_window(), driver.minimize_window()
Selenium은 크롬브라우저의 창 크기를 조절할 수 있습니다.
from selenium import webdriver
driver = webdriver.Chrome('크롬드라이버')
driver.get(url)
# 현재 브라우저 창 크기 알아내기
driver.get_window_size()
# {'width': 1051, 'height': 806} 결과
# 창크기 조절하기
driver.set_window_size(x, y)
# 예
driver.set_window_size(1920.1080)
# 최대로 화면 키우기
driver.maximize_window()
# 화면 작게만들기
driver.minimize_window()
스크롤 내리기 driver.execute_script()
크롤링을 하다보면 해당 웹페이지를 스크롤을 내려야할 경우가 생기는데요 Selnium에서는 그러한 기능을 제공합니다.
# 맨밑으로 이동하기
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
# 맨위로 이동하기
driver.execute_script("window.scrollTo(0,0)")
해당 페이지 스크린샷 찍기 driver.save_screenshot()
셀레니움은 웹브라우저를 띄우지않고도 크롤링할 수 있습니다. 그럴때 어디쯤 크롤링을 하고 있는지 확인이 필요할텐데요. 그때 사용하면 좋을거 같습니다.
# 현재 페이지 스크린샷
driver.save_screenshot("이미지 저장경로")
#예
driver.save_screenshot("../selenium_images/image1.png")
xpath 이해하기
- //: 최상위 부분을 말합니다. 최상위 element 최상위 tag
- *: 자손 태그 검색 = > div form # 띄어쓰기 = 자손태그, >꺽쇠는 자손태그
- /: 자식 태그를 검색 = > div > form 꺽쇠는 자손태그 검색
- td[2]: td태그중에서 두 번째 태그 검색 = > css selector에서는 td:nth-child(2)
아래 특정xpath을 해석해보겠습니다.
//*[@id="___gcse_0"]/div/form/table/tbody/tr/td[2]/button
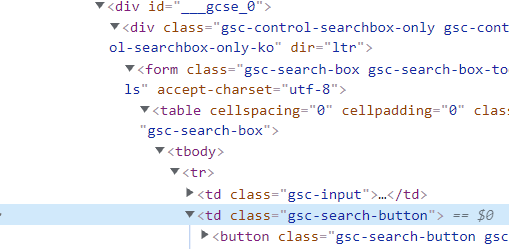
저는 이미지에 보이는 것 처럼 <td class = "gsc-search-button"> 태그를 찾을려고 합니다. 위 xpath를 해석해보면,
최상위 태그고 id가 ___gscse_0이 최상위 태그입니다 그 밑에 바로 자손태그 div자식form자식table자식tbody자식tr자식td태그들중 2번째 태그 자식 button입니다.
find by css element 태그 찾기
find_element_by_css_selector ====> find, select_one---> BeautifulSoup
find_elements_by_css_selector =====> find_all, select-----> BeautifulSoup
페이지 앞으로 가기, 뒤로가기
#뒤로가기 버튼 클릭하기
driver.back()
#앞으로가기 버튼 클릭하기
driver.forward()
현재페이지 html코드 가져오기
보통 selenium은 BeautifulSoup와 같이 사용합니다. selenium으로 특정 페이지까지 접근이 완료되었다면, 그 다음페이지부터는 BeautifulSoup로 데이터 가져오는게 더 편할 수 도 있습니다.
from selenium import webdriver
from bs4 import BeautifulSoup
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
soup
~~'Python Crawing' 카테고리의 다른 글
| Selenium - headless 와 wait 문법 사용해보기 (0) | 2021.10.12 |
|---|---|
| Selenium - iframe (0) | 2021.10.12 |
| 크롤링- 기초문법 활용 네이버 영화 평점 크롤링 (0) | 2021.10.05 |
| 크롤링 - 기초 문법 (0) | 2021.09.29 |



댓글